검증 세트(validation set): 테스트세트를 사용하지 않고 모델이 과대적합인지 과소적합인지 측정하기 위해 훈련세트를 또 나누어 만든 데이터
- 전체 데이터 중에서 60%를 훈련세트로, 20%를 테스트세트로, 20%를 검증세트로 만들어 사용한다.
1. 훈련세트에서 모델을 훈련하고 검증세트로 모델을 평가한다.
2. 테스트하고 싶은 매개변수를 바꿔가며 가장 좋은 모델을 골라 이 매개변수를 사용해 훈련세트와 검증세트를 합쳐 전체 훈련데이터에서 모델을 다시 훈련한다.
3. 테스트세트에서 최종점수를 평가한다
-> 실전에 투입했을 때 테스트세트의 점수와 비슷한 성능을 기대할 수 있을 것
판다스로 CSV데이터를 읽고 class열을 타깃으로 사용하고 나머지 alcohol, sugar, pH열은 특성배열에 저장한다.
import pandas as pd
wine = pd.read_csv('https://bit.ly/wine_csv_data')
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy()
훈련세트와 테스트세트를 나누고 훈련세트의 입력데이터와 타깃데이터를 train_input과 train_target배열에 저장한다.
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(data, target,test_size=0.2, random_state
다시 train_input과 train_target을 train_test_split()함수에 넣어 훈련세트 sub_input, sub_target과 검증세트 val_input, val_target을 만든다.
test_size 매개변수를 0.2로 지정해 train_input의 약 20%를 val_input으로 만든다
sub_input, val_input, sub_target, val_target = train_test_split(train_input, train_target, test_size=0.2, random_state=42)
print(sub_input.shape, val_input.shape)훈련세트와 검증세트의 크기를 확인해보니
(4157, 3) (1040, 3)원래 5197개였던 훈련세트가 4157개의 훈련세트로, 1040개의 검증세트로 나뉜 것을 확인할 수 있다.
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(random_state=42)
dt.fit(sub_input, sub_target)
print(dt.score(sub_input, sub_target))
print(dt.score(val_input, val_target))이렇게 만든 훈련세트와 검증세트로 모델을 만들고 평가해보았다.
0.9971133028626413
0.864423076923077훈련세트의 점수보다 검증세트의 점수가 낮은 것으로 보아 훈련세트에 과대적합 되어있음을 볼 수 있다.
교차 검증(cross validation): 훈련세트를 훈련세트와 검증세트로 분리한 뒤, 검증세트를 사용해 검증하는 방식
- 안정적인 검증 점수를 얻고 훈련에 더 많은 데이터를 사용할 수 있다.
- 검증 세트를 떼어 내어 평가하는 과정을 여러 번 반복
| 장점 | 단점 |
| ○ 모든 데이터셋을 훈련과 평가에 활용할 수 있다 ○ 정확도를 향상시킬 수 있다 ○ 데이터 부족으로 인한 과대적합을 방지할 수 있다 ○ 평가에 사용되는 데이터 편중을 막을 수 있다 ○ 평가 결과에 따라 좀 더 일반화된 모델을 만들 수 있다 |
△ 반복 횟수가 많아 모델을 훈련하고 평가하는 시간이 오래 걸린다 |
3-폴드 교차 검증(k-폴드 교차 검증, k-겹 교차 검증)

데이터의 80~90%까지 훈련에 사용할 수 있다. 검증 세트가 줄어들지만 각 폴드에서 계산한 검증 점수를 평균하여 안정된 점수로 생각할 수 있다.
사이킷런의 cross_validate()라는 교차 검증 함수를 사용해보자
이는 평가할 모델 객체를 첫 번째 매개변수로 전달하고 직접 검증 세트를 떼어내지 않고 훈련세트 전체를 이 함수에 전달한다.
from sklearn.model_selection import cross_validate
scores = cross_validate(dt, train_input, train_target)
print(scores)fit_time, score_time, test_score 키를 가진 딕셔너리를 반환한다.
{'fit_time': array([0.0076046 , 0.00728416, 0.00738478, 0.00718737, 0.006953 ]), 'score_time': array([0.00066686, 0.00066161, 0.00060678, 0.00061059, 0.00063467]), 'test_score': array([0.86923077, 0.84615385, 0.87680462, 0.84889317, 0.83541867])}fit_time: 모델을 훈련하는 시간
score_time: 모델을 검증하는 시간
각 키마다 5개의 숫자가 담겨 있는데 기본적으로 cross_validate() 함수는 5-폴드 교차 검증을 수행한다. cv 매개변수에서 폴드 수를 바꿀 수도 있다.
scores = cross_validate(dt , train_input , train_target ,cv=3)↑이런 식으로!
파라미터는 (모델, 훈련데이터의 특성, 훈련데이터의 타깃, 폴드 수)이다
import numpy as np
print(np.mean(scores['test_score']))교차검증의 최종점수는 test_score키에 담긴 5개의 점수를 평균하여 얻을 수 있다. -> 검증 폴드의 점수
0.855300214703487교차검증을 수행하면 입력한 모델에서 얻을 수 있는 최상의 검증 점수를 가늠해 볼 수 있다.
cross_validate()는 훈련세트를 섞어 폴드를 나누지 않는다. train_test_split() 함수로 전체 데이터를 섞은 후 훈련세트를 준비했기 때문에 따로 섞을 필요가 없지만 교차 검증을 할 때 훈련세트를 섞으려면 분할기(splitter)를 지정해야한다.
사이킷런의 분할기는 교차검증에서 폴드를 어떻게 나눌지 결정해준다.
- cross_validate() 함수는 기본적으로 회귀 모델일 경우 KFold분할기를 사용
- 분류 모델일 경우 타깃 클래스를 골고루 나누기 위해 StratifiedFold를 사용한다.
from sklearn.model_selection import StratifiedKFold
scores = cross_validate(dt, train_input, train_target, cv=StratifiedKFold())
print(np.mean(scores['test_score']))앞서 수행한 코드와 같다
0.855300214703487
훈련세트를 섞은 후 10-폴드 교차 검증을 수행하려면
splitter = StratifiedKFold(n_splits=10, shuffle=True, random_state=42)
scores = cross_validate(dt, train_input, train_target, cv=splitter)
print(np.mean(scores['test_score']))n_splits 매개변수: 몇(k) 폴드 교차 검증을 할지 결정
0.8574181117533719KFold클래스도 동일한 방식으로 사용할 수 있다.
결정트리의 매개변수 값을 바꿔가며 가장 좋은 성능이 나오는 모델을 찾아보자
테스트세트를 사용하지 않고 교차검증을 통해 좋은 모델을 고르면 된다!
하이퍼파라미터 튜닝: 라이브러리가 제공하는 기본값을 그대로 사용해 모델을 훈련하고, 검증세트의 점수나 교차 검증을 통해서 매개변수를 조금씩 바꿔본다.
이 매개변수를 바꿔가며 모델을 훈련하고 교차검증을 수행한다.
* 하이퍼파라미터 : 사용자 지정 파라미터
그리드 서치(Grid Search): 탐색할 매개변수를 나열하면 교차검증을 수행해 가장 좋은 검증 점수의 매개변수 조합을 선택하고 이 매개변수 조합으로 최종 모델을 훈련한다. 하이퍼파라미터 탐색을 자동으로 해주는 도구
- max_depth의 최적값은 min_samples_split 매개변수의 값이 바뀌면 함께 달라진다. 이 두 매개변수를 동시에 바꿔가며 최적의 값을 찾기 위한 도구
GridSearchCV 클래스로 하이퍼파라미터 탐색과 교차검증을 한 번에 수행할 수 있다 -> cross_validate()함수를 호출할 필요가 없다
딕셔너리 형태로 min_impurity_decrease 매개변수의 최적값을 찾아본다
* min_impurity_decrease : 최소 불순도(default = 0.0)
from sklearn.model_selection import GridSearchCV
params = {'min_impurity_decrease' : [0.0001, 0.0002, 0.0003, 0.0004, 0.0005]}0.0001부터 0.0005까지 0.0001씩 증가하는 5개의 값을 시도
GridSearchCV클래스에 탐색 대상 모델과 params 변수를 전달하여 그리드 서치 객체를 생성
gs = GridSearchCV(DecisionTreeClassifier(random_state=42), params, n_jobs=-1)결정 트리 클래스 객체 gs에 fit() 메서드를 호출한다.
그리드 서치 객체는 결정 트리 모델 min_impurity_decrease 값을 바꿔가며 총 5번 실행한다.
n_jobs 매개변수: 병렬 실행에 사용할 CPU 코어 수를 지정, 기본값은 1, -1로 지정하면 시스템에 있는 모든 코어 사용
GridSearchCV의 cv매개변수 기본값은 5이다. min_impurity_decrease 값마다 5-폴드 교차 검증을 수행한다.
gs.fit(train_input, train_target)min_impurity_decrease 값마다 5-폴드 교차 검증을 수행 -> 5 x 5 = 25개의 모델을 훈련
dt = gs.best_estimator_
print(dt.score(train_input, train_target))best_estimator_ 속성: 훈련이 끝나면 25개의 모델 중에서 검증 점수가 가장 높은 모델의 매개변수 조합으로 전체 훈련세트에서 다시 모델을 훈련한다, 최고 점수의 모델을 찾아준다
0.9615162593804117
print(gs.best_params_)best_params_ 속성: 최적의 매개변수, 최고 점수를 낸 파라미터
{'min_impurity_decrease': 0.0001}여기에서는 0.0001이 가장 좋은 값으로 선택되었다.
print(gs.cv_results_['mean_test_score'])cv_results_ 속성: 각 매개변수에서 수행한 교차검증의 평균 점수
[0.86819297 0.86453617 0.86492226 0.86780891 0.86761605]첫 번째 값(0.0001)이 가장 큰 것을 확인할 수 있다
-> 수동으로 고르지 않고 argmax() 함수를 사용해 가장 큰 값의 인덱스 추출 가능, 이 인덱스를 사용해 params 키에 저장된 매개변수 추출 가능, 이 값이 최상의 검증 점수를 만든 매개변수 조합이다
best_index = np.argmax(gs.cv_results_['mean_test_score'])
print(gs.cv_results_['params'][best_index])앞에서 출력한 gs.best_params_와 동일
{'min_impurity_decrease': 0.0001}
조금 더 복잡한 매개변수 조합을 탐색해보자
params = {'min_impurity_decrease': np.arange(0.0001, 0.001, 0.0001),
'max_depth': range(5, 20, 1),
'min_samples_split': range(2, 100, 10)}1) arange() 함수: 첫 번째 매개변수 값에서 시작해 두 번째 매개변수 값에 도달할 때까지 세 번째 매개변수 값만큼 증가 시킨다.
-> 0.0001에서 시작해 0.0001만큼씩 증가시켜 0.001까지 더한다.
2) range() 함수: 정수만 사용 가능, max_depth를 5에서 20까지 1씩 증가하면서 15개의 값을 만든다. min_samples_split은 2부터 100까지 10씩 증가시켜 10개의 값을 만든다
- min_samples_split : 나무 성장을 멈추기 위한 임계치
즉, 이 매개변수로 수행할 교차 검증 횟수는 9 * 15 * 10 = 1350개이다. 기본 5-폴드 교차 검증을 수행하므로 만들어지는 모델의 수가 6750개나 된다.
gs = GridSearchCV(DecisionTreeClassifier(random_state=42), params, n_jobs=-1)
gs.fit(train_input, train_target)
print(gs.best_params_)그리드 서치를 수행하고 최상의 매개변수 조합을 확인해보면
{'max_depth': 14, 'min_impurity_decrease': 0.0004, 'min_samples_split': 12}
print(np.max(gs.cv_results_['mean_test_score']))최상의 교차 검증 점수 확인
0.8683865773302731GridSearchCV 클래스를 사용하니 매개변수를 일일이 바꿔가며 교차 검증을 수행하지 않고 원하는 매개변수 값을 나열하면 자동으로 교차 검증을 수행해서 최상의 매개변수를 찾을 수 있다.
랜덤 서치(Random Search) : 하이퍼파라미터의 값을 랜덤하게 넣어보고 그 중 우수한 값을 보인 하이퍼파라미터를 활용해 모델을 생성한다
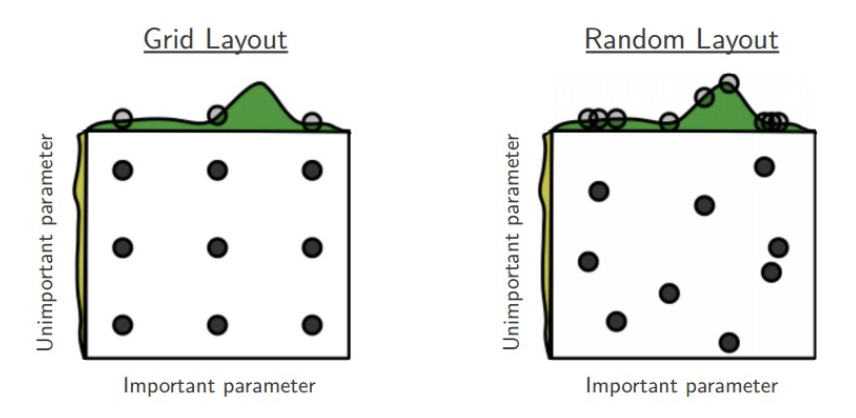
- 그리드서치는 딕셔너리에 지정한 값을 일일이 다 탐색해야한다. 임의로 정한 값이라 어떤 값이 효과적인지 알 수 없고, 입력이 되었으니 한 번씩 모델이 생성되어야한다.
- 랜덤서치는 랜덤하게 숫자를 넣은 뒤, 정해진 간격 사이에 위치한 값들에 대해서도 확률적으로 탐색이 가능하다. 최적 하이퍼파라미터를 빨리 찾을 수 있다.
from scipy.stats import uniform, randint
rgen = randint(0, 10)
rgen.rvs(10)싸이파이 stats 서브 패키지에 있는 uniform과 randint 클래스는 주어진 범위에서 고르게 값을 뽑는다. -> 균등 분포에서 샘플링한다.
randint는 정숫값을 뽑고 uniform은 실숫값을 뽑는다.
rgen = randint(0, 10) # 0부터 10까지의 범위
rgen.rvs(10)rvs는 랜덤 샘플을 생성해준다. 무작위로 표본을 만들 때 사용한다.
rvs(size, random_state)
- size: 표본 생성 시 생성될 표본의 크기
- random_state: 표본 생성 시 사용되는 시드값
array([5, 0, 7, 0, 2, 9, 5, 1, 1, 3])
ugen = uniform(0,1) # 0부터 1까지의 범위
ugen.rvs(10)uniform 클래스도 동일한 사용법으로, 0부터 1 사이에 10개의 실숫값을 추출해본다.
array([0.80014573, 0.01414502, 0.61798293, 0.83862562, 0.62798304,
0.82742719, 0.98974063, 0.01515137, 0.25313545, 0.27991184])
min_samples_leaf 매개변수 : 리프노드가 되기 위한 최소 샘플의 개수
* 어떤 노드가 분할하여 만들어질 자식 노드의 샘플 수가 이 값보다 작을 경우 분할하지 않는다
params = {'min_impurity_decrease':uniform(0.0001, 0.001),
'max_depth' : randint(20, 50),
'min_samples_split' : randint(2, 25),
'min_samples_leaf' : randint(1, 25)}min_impurity_decrease : 0.0001에서 0.001 사이의 실숫값을 샘플링
max_depth : 20부터 50까지의 정수를 샘플링
min_samples_split : 2부터 25까지 정수를 샘플링
min_samples_leaf : 1에서 25까지의 정수를 샘플링
랜덤 서치 클래스 - RandomizedSearchCV
from sklearn.model_selection import RandomizedSearchCV
gs = RandomizedSearchCV(DecisionTreeClassifier(random_state=42), params, n_iter=100, n_jobs=-1, random_state=42)
gs.fit(train_input, train_target)n_iter 매개변수 : 샘플링 횟수를 저장, 여기에서는 100번을 샘플링하여 교차 검증을 수행했다.
print(gs.best_params_)최적의 매개변수 조합을 찾아 출력해보면
{'max_depth': 39, 'min_impurity_decrease': 0.00034102546602601173, 'min_samples_leaf': 7, 'min_samples_split': 13}
print(np.max(gs.cv_results_['mean_test_score']))최고의 교차 검증 점수를 확인하면
0.8695428296438884
dt = gs.best_estimator_
print(dt.score(test_input, test_target))최적의 모델은 전체 훈련세트로 훈련되어 best_estimator_ 속성에 저장되어 있다.
이 모델을 최종 모델로 결정하고 테스트세트의 성능을 확인해본다.
0.86
∴ 테스트 세트 점수는 검증 세트에 대한 점수보다 조금 작은 것이 일반적이다.
수동으로 매개변수를 바꾸지 않고 그리드 서치나 랜덤 서치를 이용하면 된다.
'머신러닝 + 딥러닝' 카테고리의 다른 글
| [혼공머신] CHAPTER 06-1 군집 알고리즘 (0) | 2021.10.27 |
|---|---|
| [혼공머신] CHAPTER 05-3 트리의 앙상블 (0) | 2021.10.07 |
| [혼공머신] CHAPTER 05-1 결정 트리 (2) | 2021.10.02 |
| [혼공머신] CHAPTER 04-2 확률적 경사 하강법 (0) | 2021.09.29 |
| [혼공머신] CHAPTER 04-1 로지스틱 회귀 (0) | 2021.09.28 |



