SHAP를 사용하여 성인 인구 조사 데이터 세트 로드
데이터 세트 : https://archive.ics.uci.edu/ml/datasets/adult
UCI Machine Learning Repository: Adult Data Set
Adult Data Set Download: Data Folder, Data Set Description Abstract: Predict whether income exceeds $50K/yr based on census data. Also known as "Census Income" dataset. Data Set Characteristics: Multivariate Number of Instances: 48842 Area: Social Attr
archive.ics.uci.edu
데이터는 나이, 학력, 결혼상태, 직업, 인종 등등이 나타나있는 세트이다
SHAP(SHapley Additive exPlanation)

우리는 주로 예측이든 분류든 어떠한 결과값을이 얼마나 정확한지에 초점을 맞추고 있다. 하지만 모델링을 하면서 그 원인 인자를 찾고, 얼마나 결과에 영향을 주었는지 파악해야할 때가 있다. 이렇게 결과를 <설명>하는 것이 중요해지면서 XAI(eXplainable AI)가 관심을 받고 있고, 그 중 SHAP는 Shapley Value를 근간으로 하는 XAI이라고 한다.
즉, 데이터의 전체적인 영역에 대한 해석이 가능한 것
import shap
x, y = shap.datasets.adult()
x_display, y_display = shap.datasets.adult(display=True)
feature_names = list(x.columns)
feature_names결과는 첫번째 열을 list로 나열하여 본 것인데, 이는 어떤 데이터 항목들이 들어가있는지 볼 수 있음


데이터 세트의 개요
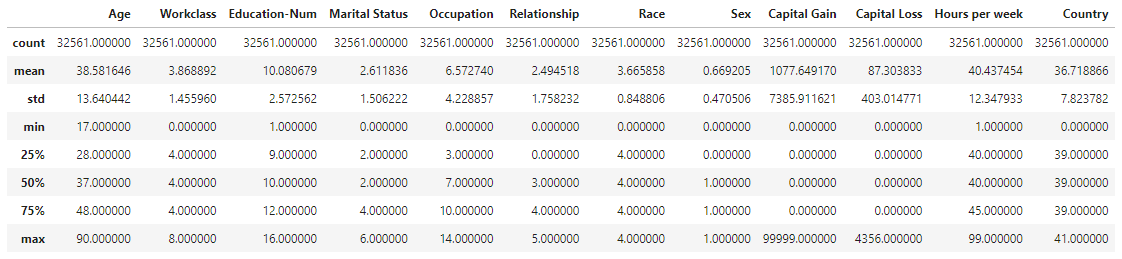
display(x.describe())
hist = x.hist(bins = 30, sharey=True, figsize=(20,10))describe()는 데이터 프레임의 열(column)별 수, 평균, 표준편차, 최소값, 4분위 수, 최대값을 보여줌
hist()는 히스토그램을 그리는 함수로, 인자로 bins는 원하는 칸의 수, sharey는 y축을 공유하도록 하는 것, figsize는 히스토그램을 그릴 크기를 의미

데이터세트를 학습, 검증 및 테스트 데이터 세트로 분할
만약, 시험을 보기 전에 출제될 시험 문제와 정답을 미리 알려주고 시험을 본다면 어떻게 될까?
누구나 시험 문제와 정답을 외운다면 당연히 100점을 맞을 것이다
-
머신러닝도 이와 마찬가지로 같은 데이터로 훈련하고 같은 데이터로 테스트한다면 모두 맞히는 것이 당연하다
머신러닝 알고리즘의 '성능'을 제대로 평가하려면 훈련 데이터와 평가에 사용할 데이터가 각각 달라야한다
-
이렇게 하기 위해서는 평가를 위해 또다른 데이터를 준비하거나, 이미 준비된 데이터 중에서 일부를 떼어내어 활용하는 방법이 있다
주로 후자의 방법을 많이 쓴다
-
그래서 평가에 사용되는 데이터를 테스트 세트(test set)라고 하고 훈련에 사용되는 데이터를 훈련 세트(train set)라고 한다
-
하지만 여기에도 문제가 있다
-
훈련 세트에서 모델을 훈련하고 테스트 세트에서 모델을 평가하는데, 테스트 세트에서 얻은 점수를 보고 '이 모델을 실전에 투입하면 이만큼의 성능을 기대할 수 있겠다'라고 할 수 있다. 일반화 성능을 가늠해 볼 수 있는데, 테스트 세트를 사용해 자꾸 성능을 확인하다보면 점점 테스트 세트에 맞추게 되는 셈이다
-
즉, 테스트 세트의 점수가 안 좋아서 테스트 세트의 점수를 높이기 위해 변수를 바꾸는 등의 행동은 결국 공부를 하지 않고 시험을 여러 번 응시해서 시험 문제를 외우는 것과 다름이 없어진다
-
테스트 세트로 인반화 성능을 올바르게 예측하려면 가능한 한 테스트 세트를 사용하지 말아야한다. 모델을 만들고 나서 마지막에 딱 한 번만 사용하는 것이 좋다
-
그래서 우리는 훈련세트를 한 번 더 나누어 검증 세트(validation set)를 만들어내야 한다
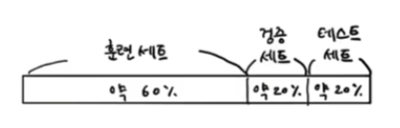
전체 데이터 중 20%를 떼어 내어 테스트 세트로 만들고 나머지 80%를 훈련 세트로 만든다. 그리고 이 훈련세트 중에서 20%를 떼어 내어 검증 세트로 만들면 된다.
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=1)
x_train_display = x_display.loc[x_train.index]sklearn을 활용해 데이터 세트를 훈련세트와 테스트세트로 분할한다. 80%는 훈련세트용이고 20%는 테스트세트용이다.
train_test_split 함수 : 데이터 세트를 분할 할 때 랜덤으로 섞은 뒤에 분할 할 수 있도록 해줌
훈련 세트를 분할하여 검증 세트를 분리
x_train, x_val, y_train, y_val = train_test_split(x_train, y_train, test_size=0.25, random_state=1)
x_train_display = x_display.loc[x_train.index]
x_val_display = x_display.loc[x_val.index]검증세트는 모델의 하이퍼파라미터를 조정하는 동안 훈련된 모델의 성능을 평가하는데 사용된다. 훈련세트의 75%가 최종 훈련세트가 되고 나머지는 검증세트이다
pandas 패키지를 이용하여 숫자 기능을 실제 레이블과 연결하여 각 데이터 세트를 명시적으로 정렬
import pandas as pd
train = pd.concat([pd.Series(y_train, index=X_train.index,
name='Income>50K', dtype=int), X_train], axis=1)
validation = pd.concat([pd.Series(y_val, index=X_val.index,
name='Income>50K', dtype=int), X_val], axis=1)
test = pd.concat([pd.Series(y_test, index=X_test.index,
name='Income>50K', dtype=int), X_test], axis=1)pd.concat() 함수 : 데이터의 속성 형태가 동일한 데이터세트끼리 합칠 때 사용하는 함수
- axis=1 : 왼쪽+오른쪽으로 합치기, 0이면 위+아래로 합치기
- objs : 데이터프레임이나 series 등과 같은 자료구조
series : 1차원 배열과 같은 자료구조
train
validation
test
훈련, 검증 데이터세트를 csv파일로 변환
train.to_csv('train.csv', index=False, header=False)
validation.to_csv('validation.csv', index=False, header=False)XGBoost 알고리즘의 입력 파일 형식과 일치하도록 하기 위함
XGBoost 알고리즘
- 그레디언트 부스팅 알고리즘을 분산환경에서도 실행할 수 있도록 구현해놓은 라이브러리
- 여러 개의 결정 트리를 조합해서 사용하는 앙상블 알고리즘
결정 트리 : 예/아니오에 대한 질문을 이어나가면서 정답을 찾아 학습하는 알고리즘(ex. 스무고개)
앙상블 학습 : 더 좋은 예측 결과를 만들기 위해 여러 개의 모델을 훈련하는 머신러닝 알고리즘
그레디언트 부스팅 : 결정 트리를 연속적으로 추가하여 손실 함수를 최소화하는 앙상블 방법
Amazon S3에 데이터 세트 업로드
import sagemaker, boto3, os
bucket = sagemaker.Session().default_bucket()
prefix = "demo-sagemaker-xgboost-adult-income-prediction"
boto3.Session().resource('s3').Bucket(bucket).Object(
os.path.join(prefix, 'data/train.csv')).upload_file('train.csv')
boto3.Session().resource('s3').Bucket(bucket).Object(
os.path.join(prefix, 'data/validation.csv')).upload_file('validation.csv')현재 sagemaker 세션에 대한 기본 버킷 URI를 설정하고, 새 폴더(prefix)를 만들어서 교육 및 검증 데이터 세트를 data 하위 폴더에 업로드한다
AWS CLI를 실행하여 CSV 파일이 S3버킷에 성공적으로 업로드 되었는지 확인
! aws s3 ls {bucket}/{prefix}/data --recursive
위와 같은 결과가 나오면 잘 업로드된 것
'AWS' 카테고리의 다른 글
| [SageMaker] 모델 배포 (1) | 2022.06.28 |
|---|---|
| [SageMaker] 모델 훈련 (1) | 2022.06.28 |
| [SageMaker] 세이지메이커 시작하기 (0) | 2022.06.28 |
| [중간점검..seminarrr...,,] AWS Greengrass (0) | 2022.05.04 |
| [Greengrass] 엣지 컴퓨팅 (0) | 2022.04.12 |



