[혼공딥] CHAPTER07-2 심층 신경망
2개의 층
from tensorflow import keras
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()전 챕터와 똑같이 데이터셋을 불러온다
from sklearn.model_selection import train_test_split
train_scaled = train_input / 255.0
train_scaled = train_scaled.reshape(-1, 28*28)
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target, test_size=0.2, random_state=42)검증세트와 훈련세트로 나눈다

은닉층(hidden layer) : 입력층과 출력층 사이에 있는 모든 층
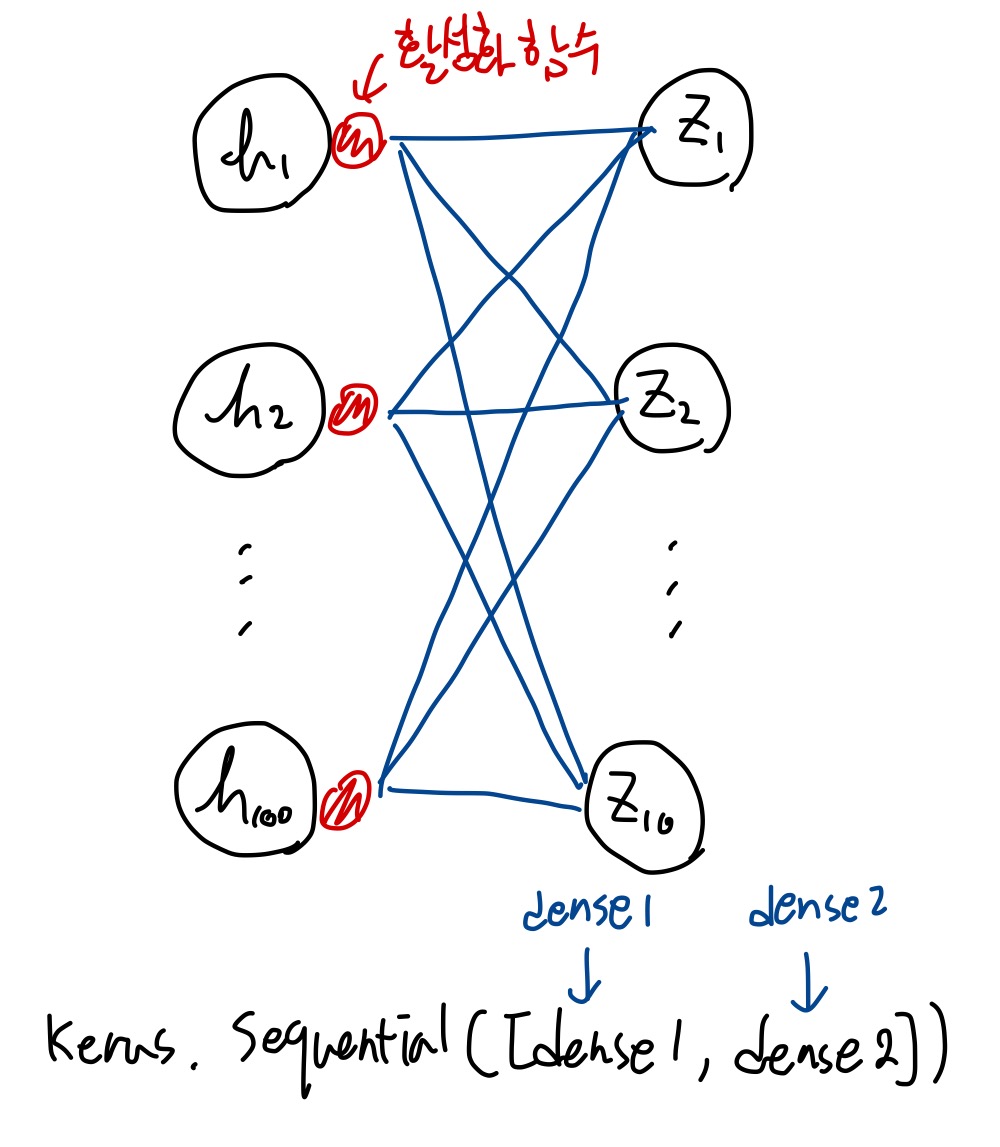
아까는 1개의 층이 있는 신경망이었고 지금은 2개의 층이 있는 신경망이다
입력층 - 28*28의 이미지를 1차원배열로 풀어서 입력을 전달하기 때문에 입력층이 784개
은닉층 - 딱히 정해지지 않는다, 출력층보다는 커야한다(작으면 손실될 수 있음)
은닉층에 활성화함수를 적용하는 이유?
: 은닉층이 활성화함수가 없이 x와 가중치의 곱으로만 표현되어 있다면 뒤의 출력층과 합쳐서 하나의 층으로 표현할 수 있을 것. 은닉층에 활성화 함수를 거쳐서 비선형 함수로 데이터를 변형해서 단순히 선형식이 합쳐지지 못하도록 해야한다.

dense1 = keras.layers.Dense(100, activation='sigmoid', input_shape=(784,))
dense2 = keras.layers.Dense(10, activation='softmax')dense1이 은닉층이고 100개의 뉴런을 가진 밀집층이다, 시그모이드 함수 사용
dense2는 출력층으로 10개의 클래스를 분류하므로 10개의 뉴런을 두었다, 소프트맥스 함수 사용
model = keras.Sequential([dense1, dense2])dense1과 dense2 객체를 Sequential 클래스에 추가하여 심층 신경망(deep neural network, DNN)을 만들어본다.
객체들을 리스트로 만들어 전달한다.
model.summary()첫 번째와 두 번째가 dense 클래스임을 나타낸다
객체를 만들 때 층의 이름을 따로 정하지 않았기 때문에 알아서 'dense'라고 이름을 붙였다.
출력되는 값은 각각 100개 / 10개의 출력이 나온다.
None이 나온 것은 fit 메서드를 호출할 때 batch_size를 적용할 수 있는데 이는 32가 기본값이다. -> 미니배치 경사 하강법
48000개를 한꺼번에 연산하는게 아니라 32개씩 잘라서 모델을 분류한다. batch_size를 바꿀 수 있는데 이때마다 모델의 구성이 달라지면 안 되기 때문에 모델을 만드는 과정을 하나로 하고, 훈련할 때 매개변수를 유연하게 바꿀 수 있도록 하는 게 바람직하다. 그래서 케라스도 한 배치의 샘플 개수의 차원을 None으로 지정해서 자연스럽게 지정할 수 있도록 했다.
Param 매개변수는 각 층에 있는 가중치와 절편, 모델 파라미터의 개수를 나타낸다.
은닉층의 파라미터 개수를 살펴보면, 입력층에 784개의 뉴런이 있고, 은닉층에는 100개의 뉴런이 있다. 가중치의 개수가 784*100개이고 100개의 뉴런은 100개의 절편이 있다. 이를 다 더하면 78500개의 가중치가 된다.
출력층의 파라미터 개수는 은닉층에는 100개의 뉴런이 있고 출력층에는 10개의 뉴런이 있어서, 가중치는 100*10개이고 절편은 10개가 있어서 1010개의 가중치가 있음을 볼 수 있다.
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 100) 78500
_________________________________________________________________
dense_2 (Dense) (None, 10) 1010
=================================================================
Total params: 79,510
Trainable params: 79,510
Non-trainable params: 0
_________________________________________________________________
층을 추가하는 다른 방법
dense 클래스를 객체화하자마자 Sequential 객체에 전달한다.
model = keras.Sequential([
keras.layers.Dense(100, activation='sigmoid', input_shape=(784,), name='hidden'),
keras.layers.Dense(10, activation='softmax', name='output')
], name='패션 MNIST 모델')- 많은 층을 추가하려면 Sequential 클래스 생성자가 매우 길어진다.
그래서,
Sequential 클래스 객체를 만들고, model 객체의 add 매서드를 사용해서 dense 클래스의 객체를 하나씩 추가한다.
model = keras.Sequential()
model.add(keras.layers.Dense(100, activation='sigmoid', input_shape=(784,)))
model.add(keras.layers.Dense(10, activation='softmax'))- 프로그램을 동적으로 조정할 수 있다. 층을 넣고 빼고 하는 걸 유연하게 할 수 있다.
모델을 어떻게 구성하는지 상관없이 모델을 훈련하는 게 가능하다
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)추가된 층이 훈련세트에 대한 성능을 향상시켰음을 볼 수 있다.
Epoch 1/5
1500/1500 [==============================] - 4s 3ms/step - loss: 0.5662 - accuracy: 0.8066
Epoch 2/5
1500/1500 [==============================] - 4s 3ms/step - loss: 0.4110 - accuracy: 0.8519
Epoch 3/5
1500/1500 [==============================] - 4s 3ms/step - loss: 0.3772 - accuracy: 0.8631
Epoch 4/5
1500/1500 [==============================] - 4s 3ms/step - loss: 0.3546 - accuracy: 0.8705
Epoch 5/5
1500/1500 [==============================] - 4s 3ms/step - loss: 0.3372 - accuracy: 0.8775
렐루 함수
시그모이드 함수의 단점: 선형 출력 값이 너무 커지거나 너무 작아질 경우에는 시그모이드 함수의 값의 변화가 굉장히 작아진다. -> 포화되어 있다. -> 층을 깊게 쌓기가 쉽지 않다
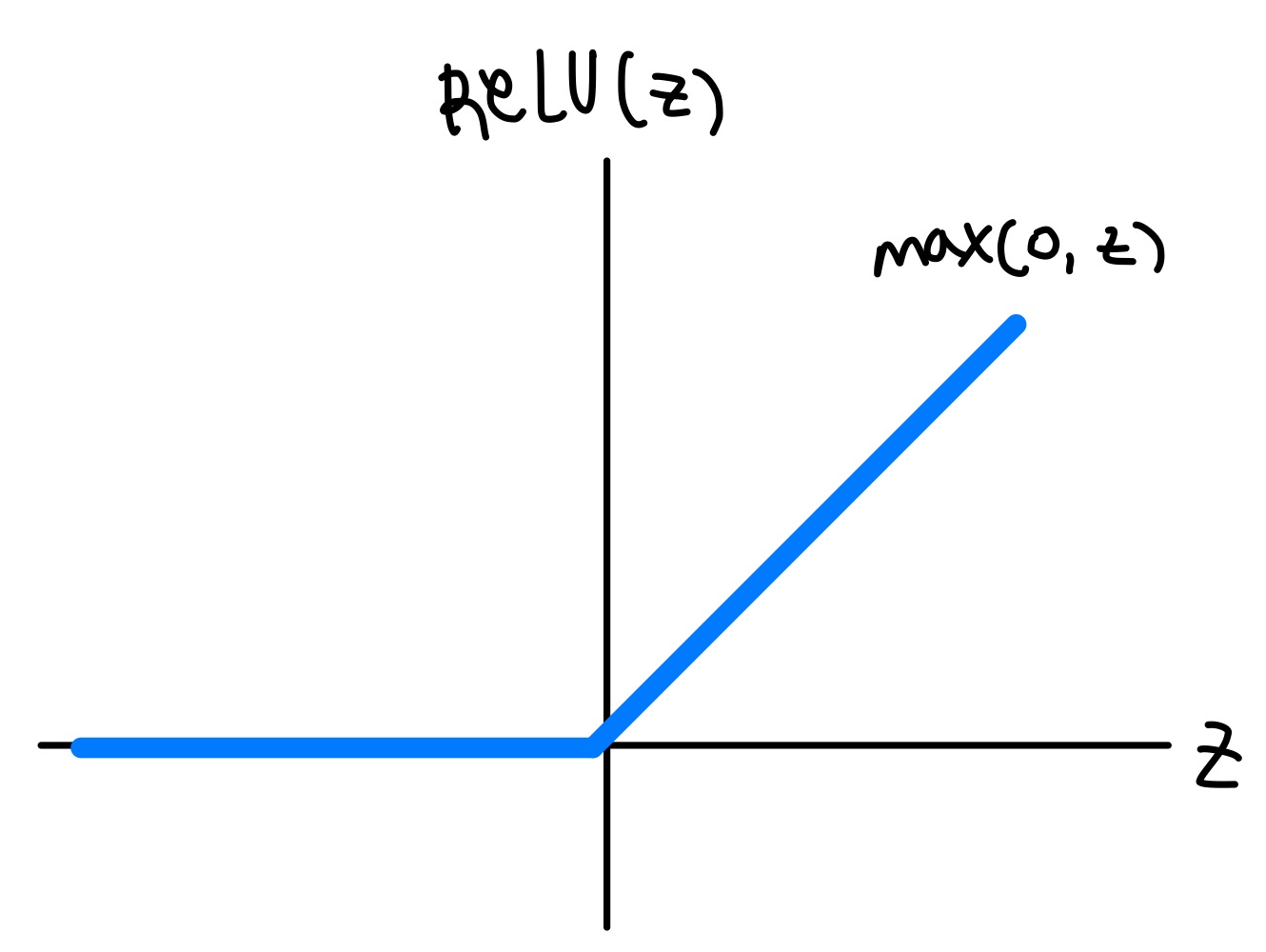
렐루 함수는 max(0, z)라고 할 수 있다. z가 0보다 크면 z를 출력하고 z가 0보다 작으면 0을 출력한다.
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28, 28)))
model.add(keras.layers.Dense(100, activation='relu')) #은닉층에 사용
model.add(keras.layers.Dense(10, activation='softmax'))
Flatten 층 : 라이브러리 구성 상 모델을 만들고 운영하기 편하게 만든 층
#model.summary()
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0
_________________________________________________________________
dense_5 (Dense) (None, 100) 78500
_________________________________________________________________
dense_6 (Dense) (None, 10) 1010
=================================================================
Total params: 79,510
Trainable params: 79,510
Non-trainable params: 0
_________________________________________________________________28*28 이미지를 784개의 1차원 배열로 풀어서 전달을 했다. 1차원 배열로 펼치는 작업을 flatten 층이 대신 해준다.
2차원 배열의 이미지를 1차원 배열로 만들지 않고 그대로 입력데이터로 사용을 해도, flatten 층이 자동으로 1차원 배열로 펼쳐서 전달을 해준다. 크기가 784로 보아, 입력값이 784개의 1차원배열임을 알 수 있다.
-> 케라스는 입력 데이터에 대한 전처리 과정을 가능한 모델에 포함시키는 것
reshape() 메서드를 적용하지 않고 모델을 훈련시켜본다.
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
train_scaled = train_input / 255.0
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target, test_size=0.2, random_state=42)
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)시그모이드 함수를 사용했을 때보다 성능이 약간 향상되었음을 볼 수 있다.
Epoch 1/5
1500/1500 [==============================] - 4s 3ms/step - loss: 0.5320 - accuracy: 0.8116
Epoch 2/5
1500/1500 [==============================] - 4s 3ms/step - loss: 0.3924 - accuracy: 0.8579
Epoch 3/5
1500/1500 [==============================] - 4s 3ms/step - loss: 0.3541 - accuracy: 0.8729
Epoch 4/5
1500/1500 [==============================] - 4s 3ms/step - loss: 0.3345 - accuracy: 0.8789
Epoch 5/5
1500/1500 [==============================] - 4s 3ms/step - loss: 0.3181 - accuracy: 0.8864
검증 세트에서의 성능을 확인해보면,
model.evaluate(val_scaled, val_target)은닉층을 추가하지 않은 경우보다 몇 퍼센트 성능이 향상되었다.
375/375 [==============================] - 1s 2ms/step - loss: 0.3777 - accuracy: 0.8757
[0.3777209520339966, 0.8756666779518127]
옵티마이저(optimizer)
: 케라스는 다양한 종류의 경사하강법을 제공

sgd는 확률적 경사 하강법, 최적화 옵티마이저가 여러 종류가 있다.
model.compile(optimizer='sgd', loss='sparse_categorical_crossentropy', metrics='accuracy')
sgd = keras.optimizers.SGD()
model.compile(optimizer=sgd, loss='sparse_categorical_crossentropy', metrics='accuracy')
#기본값이 0.01인 학습률을 바꾸고 싶다면
sgd = keras.optimizers.SGD(learning_rate=0.1)
기본 경사 하강법 옵티마이저는 SGD클래스에서 제공한다.
momentum 매개변수의 기본값은 0이다. 0보다 큰 값으로 지정하면 모멘텀 최적화(momentum optimization)를 사용한다.
SGD 클래스의 nesterov 매개변수를 기본값 False에서 True로 바꾸면 네스테로프 모멘텀 최적화(nestrov momentum optimization)를 사용한다
sgd = keras.optimizers.SGD(momentum=0.9, nesterov=True)
적응적 학습률(adaptive learning rate) : 최적값에 멀리 있는 상태면 가까이 가기 위해 빨리빨리 학습을 시키고 수렴점에 가까이 갈수록 잘 수렴하기 위해서 조금씩 조금씩 이동하기 위해 학습률을 줄인다.
- Adagrad
adagrad = keras.optimizers.Adagrad()
model.compile(optimizer=adagard, loss='sparse_categorical_crossentropy', metrics='accuracy')-RMSprop
rmsprop = keras.optimizers.RMSprop()
model.compile(optimizer=rmsprop, loss='sparse_categorical_crossentropy', metrics='accuracy')-Adam
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28, 28)))
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))Adam 클래스의 매개변수 기본값을 사용해 패션 MNIST 모델을 훈련시킨다
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)compile() 메서드의 optimizer를 'adam'으로 설정하고 5번의 에포크 동안 훈련한다
Epoch 1/5
1500/1500 [==============================] - 4s 2ms/step - loss: 0.5293 - accuracy: 0.8151
Epoch 2/5
1500/1500 [==============================] - 4s 2ms/step - loss: 0.3985 - accuracy: 0.8587
Epoch 3/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.3577 - accuracy: 0.8708
Epoch 4/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.3306 - accuracy: 0.8782
Epoch 5/5
1500/1500 [==============================] - 4s 2ms/step - loss: 0.3097 - accuracy: 0.8864RMSprop을 사용했을 때와 거의 같은 성능을 보여준다
model.evaluate(val_scaled, val_target)검증세트에서는 Adam이 RMSprop보다 나은 성능을 보여준다.
375/375 [==============================] - 1s 2ms/step - loss: 0.3520 - accuracy: 0.8720
[0.35196182131767273, 0.871999979019165]