지도 학습이란?
- 정답이 있는 데이터를 활용해 데이터를 학습시키는 것
비지도 학습이란?
- 정답이 없는 데이터를 비슷한 특징끼리 군집화 하여 새로운 데이터에 대한 결과를 예측하는 방법
CHAPTER 01에서는 도미인지 아닌지 여부를 정답으로 하였다.
지도 학습에서는 데이터와 정답을 입력(input)과 타깃(target)이라고 하고, 이 둘을 합쳐서 훈련 데이터라고 한다.
특성 : 입력으로 사용된 길이와 무게
CHAPTER 01의 문제점 : 이미 입력된 정답을 가지고 테스트했기 때문에 정확한 답을 맞추는 게 가능
머신러닝 알고리즘의 성능을 제대로 평가하려면 훈련 데이터와 평가에 사용할 데이터가 각각 달라야한다.
그래서 제대로 평가하기 위해서 이미 준비된 데이터 중에서 일부를 활용하거나 새로운 데이터를 준비해야한다.
앞으로 이미 준비된 도미와 빙어의 데이터 중에서 일부를 활용할건데 평가에 사용되는 데이터를 테스트 세트라고 하고 훈련에 사용되는 데이터를 훈련 세트라고 부른다.
앞선 챕터와 같이 도미와 빙어의 데이터를 합쳐서 하나의 리스트로 준비한다.
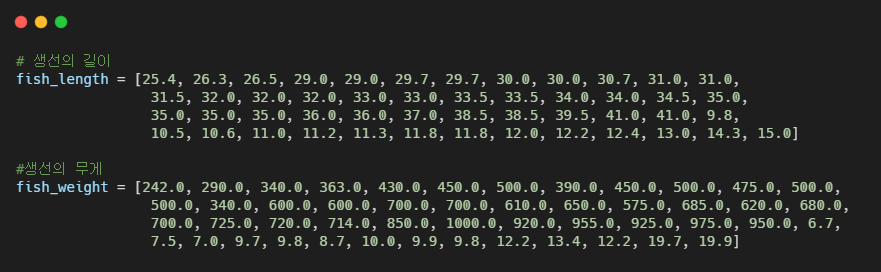
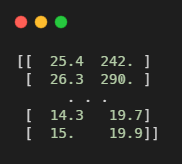
리스트를 순회하면서 생선의 길이와 무게를 하나의 2차원 리스트로 만들기

샘플 : 하나의 생선 데이터
사이킷런의 KNeighborsClassifier 클래스를 임포트하고 kn이라는 모델 객체를 만든다


이러면 훈련세트로 입력값과 타깃값 중에 35개를 사용한다는 뜻이고 테스트 세트로 나머지를 사용한다는 의미인데 이것은 문제가 있다.
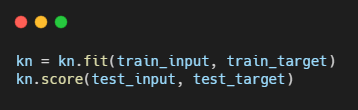

위 모델의 성능을 측정해보면 정확도가 0이 나온다. 그 이유는 훈련 세트에서 빙어가 하나도 없기 때문이다. 즉, 빙어 없이 모델을 훈련시키면 빙어를 올바르게 분류할 수 없다. 훈련 세트와 테스트 세트를 제대로 나누려면 도미와 빙어가 골고루 섞이게 만들어야 한다. 이것을 샘플링 편향이라고 한다.
샘플링 편향(sampling bias) : 훈련 세트와 테스트 세트에 샘플이 골고루 섞이지 않아 샘플링이 한쪽으로 치우쳤다는 의미
앞서 파이썬의 리스트로 2차원 리스트를 표현할 수 있지만 고차원 리스트를 표현하기 위해 넘파이(numpy)를 사용한다.

shape : 배열의 크기를 알려준다

arange() : 정수 N을 전달하면 0에서부터 N-1까지 1씩 증가하는 배열을 만든다
shuffle() : 주어진 배열을 무작위로 섞는다


잘 섞인 것을 확인할 수 있다
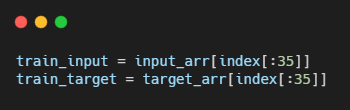
인덱스 배열의 처음 35개를 input_arr와 target_arr에 전달하여 랜덤하게 35개의 샘플을 훈련 세트로 만든다

테스트 세트가 준비가 되었다. 선점도를 그려서 훈련 세트와 테스트 세트가 잘 섞여있는지 확인해보자

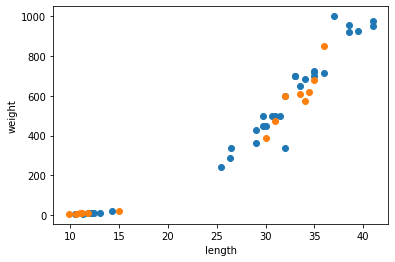
위에서 만든 훈련 세트와 테스트 세트로 k-최근접 이웃 모델을 훈련시켜 보자

정확도가 100%가 나온 것을 볼 수 있다.
하지만 그럼에도 불구하고 특성(길이, 무게)의 값이 놓인 범위가 달라 문제가 생기는 경우가 있다. 이를 두 특성의 스케일(scale)이 다르다고 한다. 여기서는 25cm, 150g의 도미를 빙어로 분류해버리는 문제가 생겨버렸다.
도미와 빙어 데이터를 준비해보자
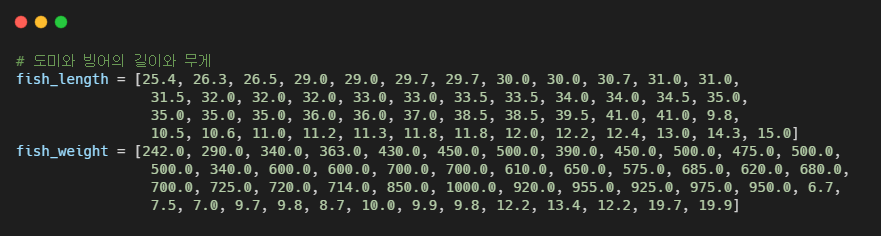
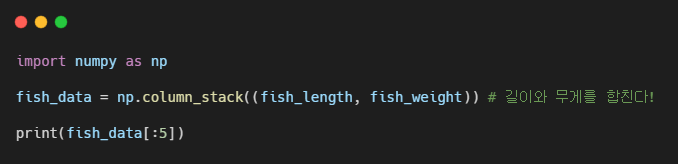
column_stack() : 전달받은 리스트를 일렬로 세운 다음 차례대로 나란히 연결한다.
np.ones() : 원하는 개수의 1을 채운 배열을 만든다
np.zeros() : 원하는 개수의 0을 채운 배열을 만든다
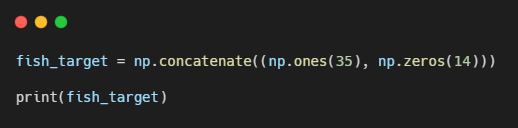
두 배열을 연결하되 첫번째 차원을 따라 배열을 연결하는 np.concatenate() 함수를 사용한다.
이제는 훈련 세트와 테스트 세트를 나눌 차례이다

샘플링 편향을 막기 위해 stratify 매개변수에 타깃 데이터를 전달해서 클래스 비율에 맞게 데이터를 나누었다.

위의 데이터들로 k-최근접 이웃을 훈련해보자


테스트 세트의 도미와 빙어를 올바르게 분류했다.
25cm 150g인 생선이 도미라고 예측할지 확인해보자
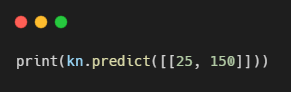

하지만 아직도 빙어라고 예측했다.
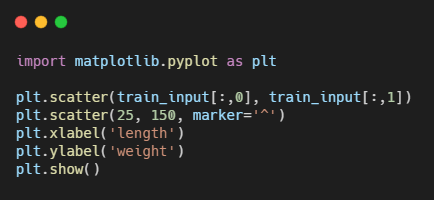

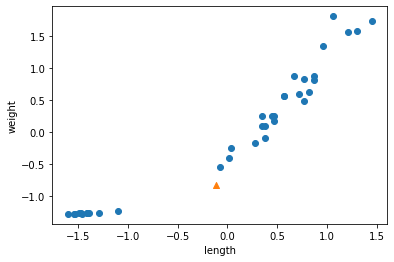
그래서 산점도 그래프를 그려보니 분명 데이터는 도미쪽에 가깝지만 이 모델은 빙어라고 판단했다.


가장 가까운 5개의 샘플에 도미가 하나밖에 포함되지 않아 세모가 도미임에도 불구하고 빙어로 나타났다.


distances배열에는 이웃 샘플까지의 거리가 있는데 직관적으로 봤을 때는 도미와 가까웠지만 사실 빙어와도 별 거리차이가 없었다. 왜냐하면 x축은 범위가 좁고, y축은 범위가 넓기 때문이다. y축으로 조금만 멀어져도 거리가 아주 큰 값으로 계산된 것이다.
즉, 길이와 무게 두 특성의 값이 놓인 범위가 매우 달라 두 특성의 스케일이 달라진 것이다. 이렇게 데이터를 표현하는 기준이 다르면 알고리즘을 제대로 예측할 수 없다. 따라서, 알고리즘들은 샘플 간의 거리에 영향을 많이 받아서 제대로 사용하려면 특성값을 일정한 기준으로 맞춰야한다. 이것을 데이터 전처리라고 부른다.
지금은 각 특성값이 0에서 표준편차의 몇 배만큼 떨어져 있는지를 나타내기 위해 표준점수를 사용할 것이다.
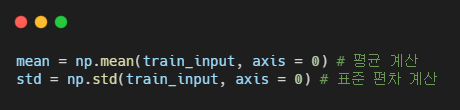
이를 표준점수로 변환하자

훈련세트의 평균과 표준편차를 이용해서 변환해야한다.
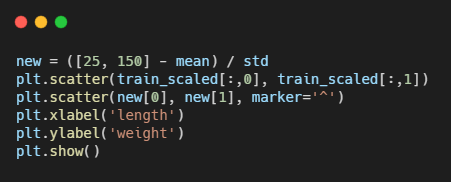
다시 k-최근접 이웃 모델을 훈련시켜보자

훈련 세트를 변환한 방식 그래도 테스트 세트를 변환해야한다!

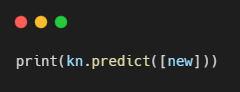

정확하게 도미로 예측했음을 알 수 있다.


다시 산점도를 그려보니 세모 샘플에서 가장 가까운 샘플은 모두 도미로 예측했음을 확인할 수 있다.
'머신러닝 + 딥러닝' 카테고리의 다른 글
| [혼공머신] CHAPTER 04-1 로지스틱 회귀 (0) | 2021.09.28 |
|---|---|
| [혼공머신] CHAPTER 03-3 특성공학과 규제 (1) | 2021.09.23 |
| [혼공머신] CHAPTER 03-2 선형회귀 (1) | 2021.09.20 |
| [혼공머신] CHAPTER 03-1 k-최근접 이웃 회귀 (0) | 2021.09.16 |
| [혼공머신] CHAPTER 01 나의 첫 머신러닝 (0) | 2021.09.10 |



