회귀(regression)
- 임의의 어떤 숫자를 예측하는 문제
- 두 변수 사이의 상관관계를 분석하는 방법
k-최근접 이웃 회귀
- 분류와 같이 예측하려는 샘플에 가장 가까운 샘플 k개를 선택
- 이웃 샘플의 수치를 활용해 새로운 샘플 x의 타깃은 평균으로 예측
1. 데이터 산점도

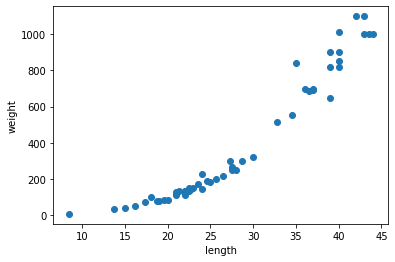
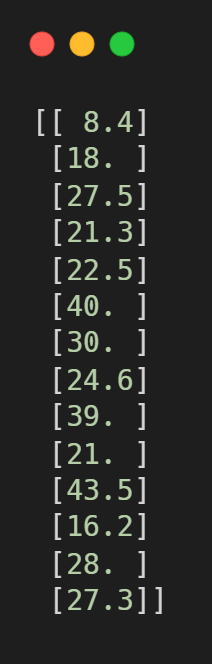
- 2장에서는 특성을 2개를 사용해서 열이 2개인 2차원 배열을 사용했지만, 여기에서는 특성 1개만 사용해야해서 수동으로 2차원 배열을 만들어야한다. 그래서 넘파이 배열이 크기를 바꿀 수 있는 reshape() 메서드를 사용한다.
reshape( )




이런 식으로 reshape()를 이용해 배열의 크기를 변경한다.
reshape(-1, n) : 크기에 -1을 지정하면 나머지 원소 개수로 모두 채우라는 의미


KNeighborsRegressor
- 사이킷런에서 k-최근접 이웃 회귀 알고리즘을 구현한 클래스


분류의 경우에는 테스트 세트의 점수는 정답을 맞힌 개수의 비율로 정확도라고 한다.
회귀에서는 정확한 숫자를 맞힌다는 것은 거의 불가능 -> 예측하는 값이나 타깃 모두 임의의 수치이다
이는 회귀에서는 결정계수(coefficient of determination)이라는 값으로 평가한다.
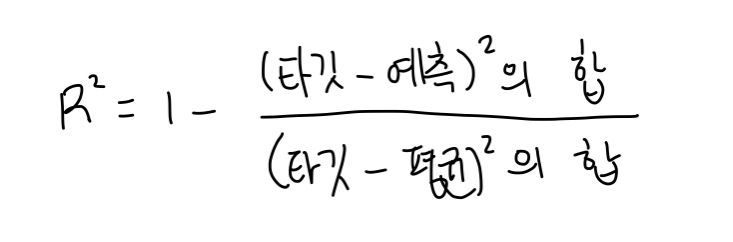
i) 예측이 평균과 비슷해지면 분모와 분자가 비슷해져서 1에 가까워진다 >> 결정계수가 0이 되어 좋지 않다!
ii) 예측이 타깃을 정확하게 맞추면 분자가 0에 가까워진다 >> 결정계수가 1이 되면 완벽하게 예측했다는 의미!
만약, 결정계수가 음수가 된다면 평균값 예측보다 못하다는 의미이다.
>>타깃과 예측한 값 사이의 차이 구하기
mean_absolute_error
- 타깃과 예측의 절대값 오차를 평균하여 반환

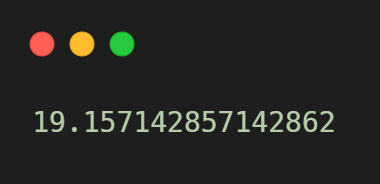
- 예측이 평균적으로 19g 정도 타깃값과 다르다
- (예측값 - 실제값)의 절댓값을 평균한 것
- 절댓값으로 계산하면 오차의 거리를 계산하므로 보다 정확한 오차를 확인할 수 있다

- ME(Mean Error) : 평균오차, 예측값이 실제값보다 작은 경우 오차가 음수로 나타내어져 오차의 평균이 +-되어 줄어들게 된다

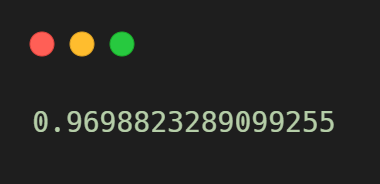
0.99(테스트세트 점수) vs 0.96(훈련세트 점수) : 과소적합(underfitting)
과소적합 : 훈련세트보다 테스트세트의 점수가 높거나 두 점수가 모두 낮은 경우
- 모델이 너무 단순하여 훈련세트에 적절히 훈련되지 않은 경우
과대적합 : 훈련세트에서 점수가 굉장히 좋았는데 테스트세트에서는 점수가 굉장히 나쁜 경우
- 훈련세트에만 잘 맞는 모델이라 테스트 세트와 나중에 실전에 투입하여 새로운 샘플에 대한 예측을 만들 때 잘 동작하지 않을 것
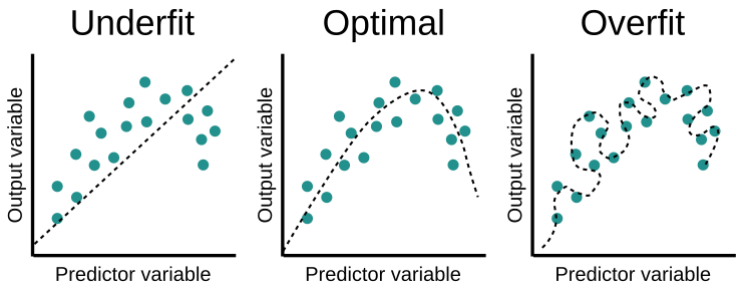
>> 모델을 복잡하게 만든다!

모델복잡도 : 모델이 가진 학습 가능한 가중치 개수
모델복잡도가 높아질수록 훈련세트의 정확도는 높아지지만 최적점 이후로 정확도가 감소한다 -> 모델이 복잡해서 훈련세트에만 잘 맞는 형태로 만들어지면 훈련세트에서만 좋은 성능을 내기 때문이다
k-최근접 이웃 알고리즘의 k개수를 줄인다 -> 훈련세트에 있는 국지적인 패턴에 민감해진다


k값을 줄였더니 훈련세트의 결정계수 점수가 높아졌다.
-> 훈련세트의 크기, 모델 복잡도가 높다고 해서 절대적으로 성능이 높아지는 것이 아니다. 여러가지 관점의 그래프 해석을 통해 최적점을 찾아내야한다!


테스트세트의 점수를 확인해보면 테스트세트의 점수가 훈련세트보다 낮아졌으므로 과소적합 문제를 해결했다!
성공적으로 회귀 모델을 훈련했다.
129p 2번 확인문제

k-최근접 이웃 회귀 모델의 k값이
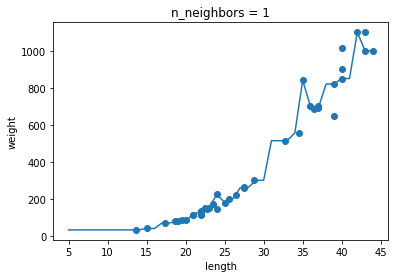
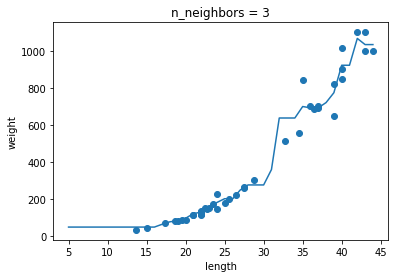
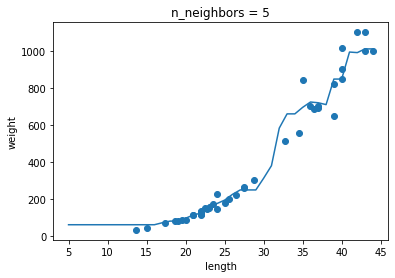
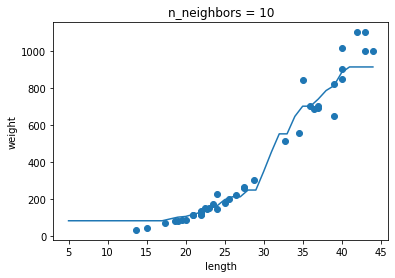
- k의 값이 1일 때 : 과대적합
- k의 값이 5, 10일 때 : 과소적합
'머신러닝 + 딥러닝' 카테고리의 다른 글
| [혼공머신] CHAPTER 04-1 로지스틱 회귀 (0) | 2021.09.28 |
|---|---|
| [혼공머신] CHAPTER 03-3 특성공학과 규제 (1) | 2021.09.23 |
| [혼공머신] CHAPTER 03-2 선형회귀 (1) | 2021.09.20 |
| [혼공머신] CHAPTER 02 데이터 다루기 (0) | 2021.09.10 |
| [혼공머신] CHAPTER 01 나의 첫 머신러닝 (0) | 2021.09.10 |



